Project 7: Leveraging Machine Learning to Detect Fraudulent Transactions
Objective of this Project
In an era where e-commerce is taking over the world, the Fraud industry is massively growing and getting creative at the same time.Therefore, Bank Clients are looking for services that provide the best security and protection against against Fraudulent Transactions. Due to the ever-increasing online transactions and production of large volumes of customer data, it is possible to leaverage machine learning as an effective tool to detect and counter frauds, assuring clients security and minimalizing organization losses.
Exploratory Data Analysis and Feature Engineering
- Mining insights from Exploratory Data Analysis to identify what features contribute to fraudulent cases.
- Undersampling Legit Transaction samples instead of using SMOTE() for Oversampling Fraudulent Transactions for simplicity as dataset is highly unbalanced, the positive class (frauds) account for 0.172% of all transactions.
- Leveraging Mutual Information Feature Selection f-test for measuring the reduction of uncertainty of one variable given the value of the other variable. In short, tells us dependance of the features with our label.
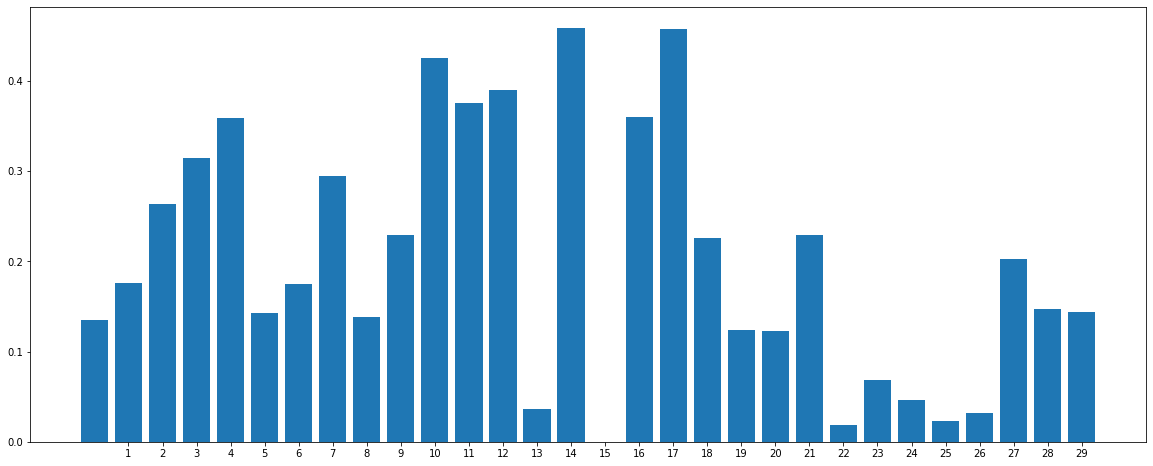
Feature Dependance
Model Building
- I tried eight different classifiers with a cross-validation approach that resamples different portions of the data to test and train a model on different iterations.This maintains the randomness and avoids any bias towards any specific samples.
- After 10 iterations, the LGBM , RF, DT and XGB classifiers have performed relatively better than the other as ensemble and tree structured algorithms tend to perform better. My goal was to utilize the Optuna Hyperparamater framework to hypertune a more complex model, hence I chose the LGBM classifier.
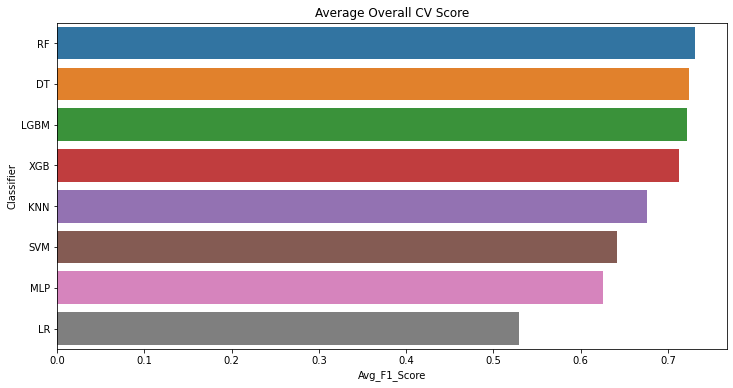
Model CV Scores
Optuna Hyperparameter Tuning
Most of the LGBM paraemeters overlap and trying to manually find the most efficient parameters can be a big mistake causing overfitting. Therefore we rely on a hyperparameter tuning framework such as Optuna.
Why Optuna?
Other opimization tools for tuning parameters like GridSearchCV or RandomizedSearchCV can become very expensive and time consuming for complex models especially when you are ensembling many models to create a final model. Optuna not only handles these limitations by parallelizing hyperparameter searches over multiple threads or processes but also allows us to prune unpromising trials. i.e we can always start over the tuning without losing historical data.
Model Evaluation and Results
-
After Finding the best Hyperparameters and Tuning our LGBM Classifier the overall accuracy and the F1 score increased on the Test data.
-
Also as you can see in the confusion matrix below, the number of False negatives are less than the number of False Positives . i.e the number of Fraudulent transactions predicted as legit are less than the number of Legit transactions predicted as Fraudulent ones. This is crucial as the loss for inaccurately predicting a fraudulent transaction as legit is way more damaging.
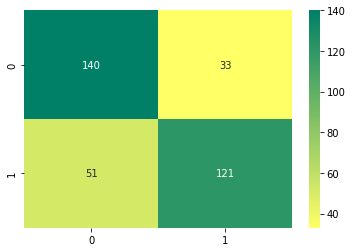
Confusion Matrix
Please Check out my Github Repository for all the details: Link to Github Repository